- Pre-processing for Text Analytics
- Linguistics 101
- Crash course for R
Linguistic Analysis and Data Science
lecture 03
謝舒凱 Graduate Institute of Linguistics, NTU
大綱
回味一下
用 linux 指令
- 建立目錄
~/lads/data/week4 - 抓 Charles Dickens 的 Oliver Twist (
http://www.gutenberg.org/cache/epub/730/pg730.txt) 丟到這個目錄,改檔案名字為dickens.txt - 移除文本中的 header 及 footer,存成
dickens-clean.txt
一種作法
curl -s http://www.gutenberg.org/cache/epub/730/pg730.txt -o dickens.txt
less -N dickens.txt
# 利用 G 和上下頁鍵
sed '1,150d' dickens.txt > dickens-noheader.txt
sed '18682,19052d' dickens-noheader.txt > dickens-clean.txt
再多練習一下 (分組做)
用 linux 指令
- 全部去標點去數字去空白,並改成小寫之後建立詞頻表
- 這個詞頻表中有一個詞彙
bumble吸引了我們的目光,請用grep指令列出在它dickens-clean.txt所在的地方(順便加上行數,與給它點顏色如何)
一種作法
(請挑戰最精簡作法$\rightarrow$可以立刻留名在 slide!)
tr -d [:punct:] < dickens-clean.txt | tr -d [:digit:] |
tr [:upper:] [:lower:] | tr -d '\r'| tr ' ' '\n' | sort | uniq -c |
sort -r -g > dickens-wordfreq.txt
grep -E -n --color=auto "(B|b)umble" dickens-clean.txt
離題一下
這件事這樣方法花了妳多少時間 (less than ONE second!!)

簡言之
在還不會用 R 處理時,可以利用 linux 指令或是 R 套件提供的功能來做前處理。
- 大小寫轉換
- 標點符號移除
- 數字移除
- URLs 移除
- 表情符號
- 停用詞移除 (stop words removal)
- 詞目化 (lemmatization)、詞幹化 (stemmming)
- 分詞 (tokenization)
- 詞類自動標記 (POS tagging)
中文文本到詞頻表的管線處理 pipeline
- 建立一個 jieba.R,放到處理資料的目錄下
# thanks to simon
library(jiebaR)
txt = scan('stdin', what = 'char')
words_vector = worker() <= txt
words_char = paste(words_vector, collapse = ' ')
cat(words_char)
- 測一下魯迅
curl -s http://www.gutenberg.org/files/27166/27166-0.txt -o luxun.txt
cat luxun.txt | Rscript jieba.R | tr ' ' '\n' | sort | uniq -c -g | sort -r > luxun-wordfreq.txt
問題:御姐愛不愛
- 新詞 (neologisms) 的複雜遠超過想像:可參見 Hsieh 2015 AsiaLex invited talk
- 自訂詞表是第一步
ShowDictPath() ### Show dict path, find and edit the "user.dict.utf8"
Exercise
從 GQ.txt 找一個不想被斷開的詞(如「卡娃伊」) 加入 jieba 詞表(user.dict.utf8),重跑一次詞頻表,看看「卡娃伊」在不在裡面。
cat GQ.txt | Rscript jieba.R | tr ' ' '\n' | sort | uniq -c | sort -r -g > GQ-wordfreq.txt
grep '卡娃伊' GQ.txt
grep '卡娃伊' GQ-wordfreq.txt
# 增添卡娃伊到詞表之後重跑一次第一行..................
grep '卡娃伊' GQ-wordfreq.txt

[pic source]http://home.gamer.com.tw/TrackBack.php?sn=717348
Corpus and Crawler Issues
還有。。。
- 萬一我要處理的文本超過一個檔案?
- 萬一網站沒有提供好心的 text /csv 檔?
- 萬一我想要動態持續抓檔 (monitoring corpus)?
Stay tuned, 並請期待本課程線上書籍。
大綱
- Pre-processing for Text Analytics
Linguistics 101- Crash course for R
Linguistics 101
- 這個階段先碰到了 構詞學 (morphology)
In linguistics, morphology is the identification, analysis and description of the structure of a given language's morphemes and other linguistic units, such as root words, affixes, parts of speech, intonations and stresses, or implied context. (wiki)
中文斷詞(分詞)問題
- 先想像「字」「詞」有何不同?(下次細談)
- 許多人把它當成是處理階段,而不是「問題」或是「假說」
- 造成的大數據大雜訊的效應 (Hsieh, 2015)
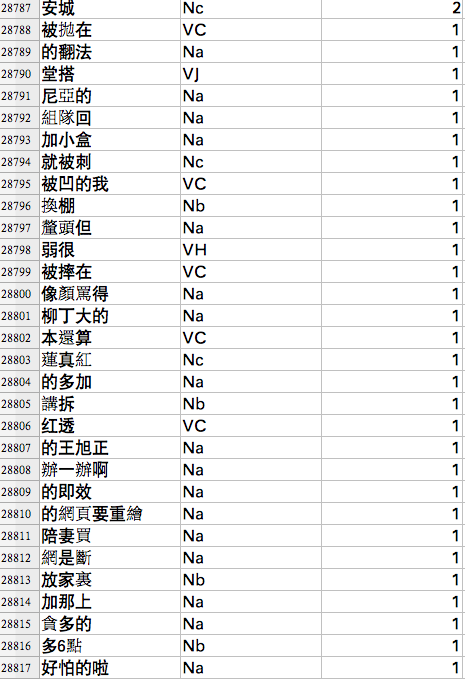
目前解法
- 自備詞表 domain lexicon
- unsupervised learning
- Pre-processing for Text Analytics
- Linguistics 101
Crash course for R
Learn R in 10 Minutes
Check week4.R in ceiba (revised from http://learnxinyminutes.com/docs/r/)
Homework Bonus (20151008)
- 建立妳認為最適合台灣中文的停用詞表與表情符號表 (Ceiba 有幾個現成的提供參考),並說明理由與作法。可以參考諸如 [Automatic Construction of Chinese Stop Word List] 學術論文。(20 分)
- 「的」通常都在各種停用詞表中,但是多一點語言學素養,你就知道問題沒那麼簡單。
舉個例子:「馬的政府」「老闆對我們是很 nice 的」「好der」